Image Captioning
Description
Image captioning aims to detect information by describing the image content through
image and text processing techniques. Recent progress in artificial intelligence (AI) has
greatly improved the performance of models.
However, the results are still not sufficiently
satisfying. Machines cannot imitate human
brains and the way they communicate, so it remains an ongoing task.
This project focuses on
the development of an image captioning system,
a novel approach merging computer vision and
natural language processing. Leveraging deep
learning techniques, the system aims to automatically generate descriptive and contextually
relevant captions for input images. By employing convolutional neural networks (CNNs) for
image feature extraction and recurrent neural
networks (RNNs) or long short-term memory
(LSTM) for language modeling and adapting
attention mechanism and GloVe word embeddings to enhance the model, the model learns
intricate relationships between visual content
and textual descriptions
Architecture
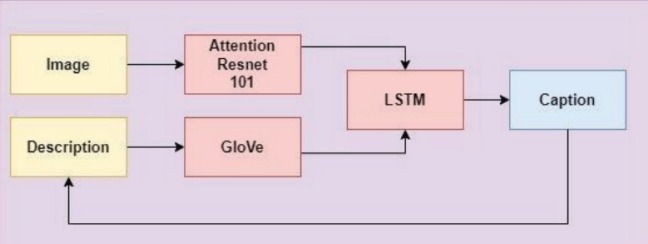
- Convolutional and Recurrent networks are the head and tail of the encoder decoder model. The convolution neural network works on the two dimensional image data and can be used in other dimensional data too. Use ResNet-50 to extract visual features from images. These features will serve as the input to our model.
- Implement an attention mechanism that combines image features and word embeddings. This allows our model to give more attention to certain image regions when generating specific words in the caption.
- Use LSTM (Long Short-Term Memory) as the recurrent neural network decoder. LSTM works by taking the image features and generating captions word by word. Maintain a memory of the previously generated words, enabling it to capture sequential dependencies in the text. Incorporate attention mechanisms to allow the model to focus on different parts of the image and provide more contextually relevant captions.
- Incorporate gloVe word embeddings into the model. These embeddings enhance the model’s ability to understand word semantics, generalize to diverse vocabulary, and improve overall performance.
The encoder part receives the image as input and generates a feature vector of high dimensions. The 3 image goes through the layers of the Encoder model that converts the image to feature vector. The system does not understand anything but 0’s and 1’s and thus the image is converted to 0s and 1s. The image vector created is the form of binary format. The encoder is a group of convolutions that uses filters and uses pooling to help the system to focus on certain regions of the image. The encoded features from the encoder are given as input to the decoder. The decoder takes this high dimension features and generates a semantic segmentation mask. It is a process of recurrent units where it predicts an output at each stage. It accepts a hidden state and produces an output and its own hidden state. Various activation functions are used in the encoder-decoder model as per the application of the user.
Encoder
Attention Mechanism
Decoder
GloVe Embeddings
By organizing these components into our model architecture, we can create a powerful system for generating image captions. The feature extraction step with ResNet-50 provides the visual context, the attention mechanism refines the focus, LSTM handles sequential word generation, and GloVe embeddings enhance the language understanding. This combination leverages both visual and semantic information to generate contextually relevant and coherent image captions.
Future Development
- To get more accuracy in this model.
- I would also like to develop this using Transformers, which is the current trend.